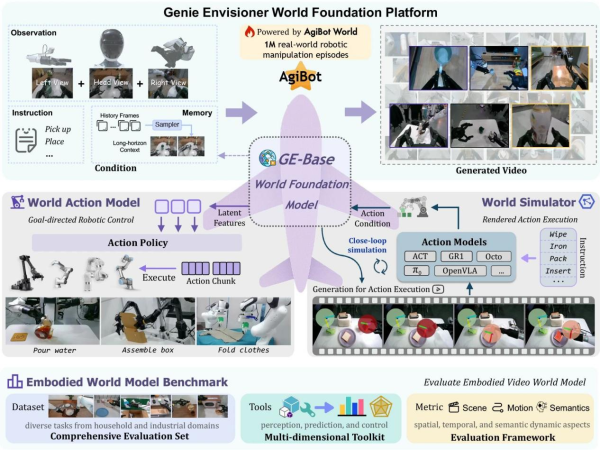
Agibot Released the Industry First Open-Source Robot World Model Platform – Genie Envisioner
Shanghai, China, 17th Oct 2025 — Recently, Agibot has officially launched Genie Envisioner (GE), a unified world model platform for real-world robot control. Departing from the traditional fragmented pipeline of data-training-evaluation, GE integrates future frame prediction, policy learning, and simulation evaluation for the first time into a closed-loop architecture centered on video generation. This enables robots to perform end-to-end reasoning and execution—from seeing to thinking to acting—within the same world model. Trained on 3,000 hours of real robot data, GE-Act not only significantly surpasses existing State-of-The-Art (SOTA) methods in cross-platform generalization and long-horizon task execution but also opens up a new technical pathway for embodied intelligence from visual understanding to action execution.
Current robot learning systems typically adopt a phased development model—data collection, model training, and policy evaluation—where each stage is independent and requires specialized infrastructure and task-specific tuning. This fragmented architecture increases development complexity, prolongs iteration cycles, and limits system scalability. The GE platform addresses this by constructing a unified video-generative world model that integrates these disparate stages into a closed-loop system. Built upon approximately 3,000 hours of real robot manipulation video data, GE establishes a direct mapping from language instructions to the visual space, preserving the complete spatiotemporal information of robot-environment interactions.
01/ Core Innovation: A Vision-Centric World Modeling Paradigm
The core breakthrough of GE lies in constructing a vision-centric modeling paradigm based on world models. Unlike mainstream Vision-Language-Action (VLA) methods that rely on Vision-Language Models (VLMs) to map visual inputs into a linguistic space for indirect modeling, GE directly models the interaction dynamics between the robot and the environment within the visual space. This approach fully retains the spatial structures and temporal evolution information during manipulation, achieving more accurate and direct modeling of robot-environment dynamics. This vision-centric paradigm offers two key advantages:
Efficient Cross-Platform Generalization Capability: Leveraging powerful pre-training in the visual space, GE-Act requires minimal data for cross-platform transfer. On new robot platforms like the Agilex Cobot Magic and Dual Franka, GE-Act achieved high-quality task execution using only 1 hour (approximately 250 demonstrations) of teleoperation data. In contrast, even models like π0 and GR00T, which are pre-trained on large-scale multi-embodiment data, underperformed GE-Act with the same amount of data. This efficient generalization stems from the universal manipulation representations learned by GE-Base in the visual space. By directly modeling visual dynamics instead of relying on linguistic abstractions, the model captures underlying physical laws and manipulation patterns shared across platforms, enabling rapid adaptation.
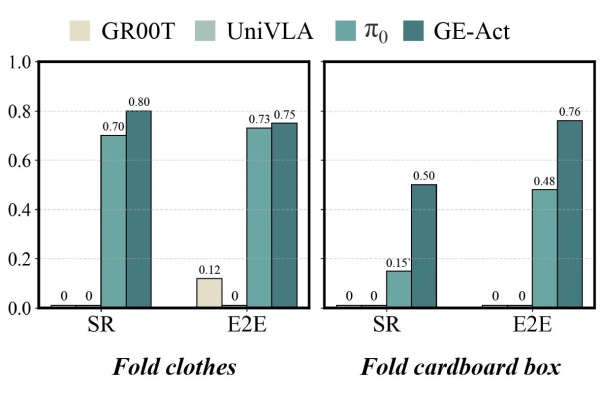
Accurate Execution Capability for Long-Horizon Tasks: More importantly, vision-centric modeling endows GE with powerful future spatiotemporal prediction capabilities. By explicitly modeling temporal evolution in the visual space, GE-Act can plan and execute complex tasks requiring long-term reasoning. In ultra-long-step tasks such as folding a cardboard box, GE-Act demonstrated performance far exceeding existing SOTA methods. Taking box folding as an example, this task requires the precise execution of over 10 consecutive sub-steps, each dependent on the accurate completion of the previous ones. GE-Act achieved a 76% success rate, while π0 (specifically optimized for deformable object manipulation) reached only 48%, and UniVLA and GR00T failed completely (0% success rate). This enhancement in long-horizon execution capability stems not only from GE’s visual world modeling but also benefits from the innovatively designed sparse memory module, which helps the robot selectively retain key historical information, maintaining precise contextual understanding in long-term tasks. By predicting future visual states, GE-Act can foresee the long-term consequences of actions, thereby generating more coherent and stable manipulation sequences. In comparison, language-space-based methods are prone to error accumulation and semantic drift in long-horizon tasks.

02/ Technical Architecture: Three Core Components
Based on the vision-centric modeling concept, the GE platform consists of three tightly integrated components:
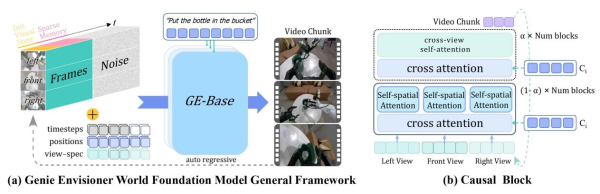
GE-Base: Multi-View Video World Foundation Model: GE-Base is the core foundation of the entire platform. It employs an autoregressive video generation framework, segmenting output into discrete video chunks, each containing N frames. The model’s key innovations lie in its multi-view generation capability and sparse memory mechanism. By simultaneously processing inputs from three viewpoints (head camera and two wrist cameras), GE-Base maintains spatial consistency and captures the complete manipulation scene. The sparse memory mechanism enhances long-term reasoning by randomly sampling historical frames, enabling the model to handle manipulation tasks lasting several minutes while maintaining temporal coherence.
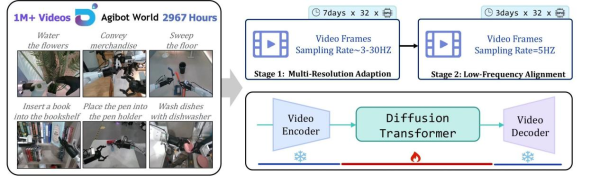
Training uses a two-stage strategy: first, temporal adaptation training (GE-Base-MR) with multi-resolution sampling at 3-30Hz makes the model robust to different motion speeds; subsequently, policy alignment fine-tuning (GE-Base-LF) at a fixed 5Hz sampling rate aligns with the temporal abstraction of downstream action modeling. The entire training was completed in about 10 days using 32 A100 GPUs on the AgiBot-World-Beta dataset, comprising approximately 3,000 hours and over 1 million real robot data instances.
GE-Act: Parallel Flow Matching Action Model: GE-Act serves as a plug-and-play action module, converting the visual latent representations from GE-Base into executable robot control commands through a lightweight architecture with 160M parameters. Its design cleverly parallels GE-Base’s visual backbone, using DiT blocks with the same network depth as GE-Base but smaller hidden dimensions for efficiency. Via a cross-attention mechanism, the action pathway fully utilizes semantic information from visual features, ensuring generated actions align with task instructions.
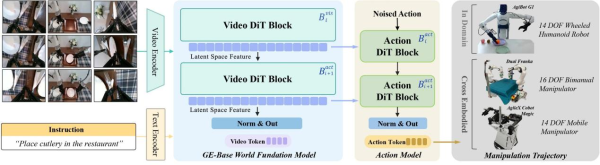
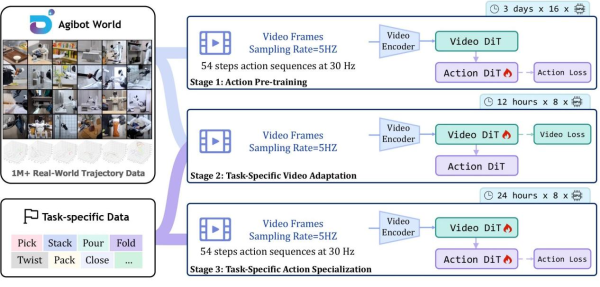
GE-Act’s training involves three stages: action pre-training projects visual representations into the action policy space; task-specific video adaptation updates the visual generation component for specific tasks; task-specific action fine-tuning refines the full model to capture fine-grained control dynamics. Notably, its asynchronous inference mode is key: the video DiT runs at 5Hz for single-step denoising, while the action model runs at 30Hz for 5-step denoising. This “slow-fast” two-layer optimization enables the system to complete 54-step action inference in 200ms on an onboard RTX 4090 GPU, achieving real-time control.
GE-Sim: Hierarchical Action-Conditioned Simulator: GE-Sim extends GE-Base’s generative capability into an action-conditioned neural simulator, enabling precise visual prediction through a hierarchical action conditioning mechanism. This mechanism includes two key components: Pose2Image conditioning projects 7-degree-of-freedom end-effector poses (position, orientation, gripper state) into the image space, generating spatially aligned pose images via camera calibration; Motion vectors calculate the incremental motion between consecutive poses, encoded as motion tokens and injected into each DiT block via cross-attention.
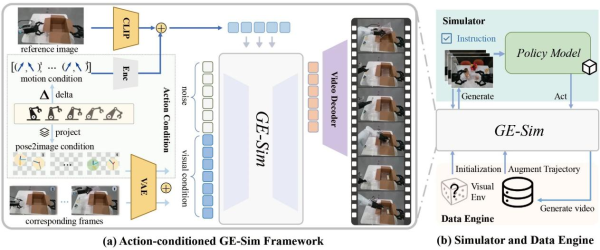
This design allows GE-Sim to accurately translate low-level control commands into visual predictions, supporting closed-loop policy evaluation. In practice, action trajectories generated by the policy model are converted by GE-Sim into future visual states; these generated videos are then fed back to the policy model to produce the next actions, forming a complete simulation loop. Parallelized on distributed clusters, GE-Sim can evaluate thousands of policy rollouts per hour, providing an efficient evaluation platform for large-scale policy optimization. Furthermore, GE-Sim also acts as a data engine, generating diverse training data by executing the same action trajectories under different initial visual conditions.

These three components work closely together to form a complete vision-centric robot learning platform: GE-Base provides powerful visual world modeling capabilities, GE-Act enables efficient conversion from vision to action, and GE-Sim supports large-scale policy evaluation and data generation, collectively advancing embodied intelligence.
EWMBench: World Model Evaluation Suite
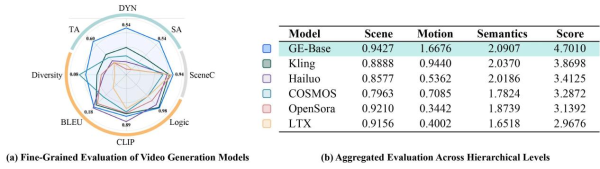
Additionally, to evaluate the quality of world models for embodied tasks, the team developed the EWMBench evaluation suite alongside the core GE components. It provides comprehensive scoring across dimensions including scene consistency, trajectory accuracy, motion dynamics consistency, and semantic alignment. Subjective ratings from multiple experts showed high consistency with GE-Bench rankings, validating its reliability for assessing robot task relevance. In comparisons with advanced models like Kling, Hailuo, and OpenSora, GE-Base achieved top results on multiple key metrics reflecting visual modeling quality, aligning closely with human judgment.
Open-Source Plan & Future Outlook
The team will open-source all code, pre-trained models, and evaluation tools. Through its vision-centric world modeling, GE pioneers a new technical path for robot learning. The release of GE marks a shift for robots from passive execution towards active ‘imagine-verify-act’ cycles. In the future, the platform will be expanded to incorporate more sensor modalities, support full-body mobility and human-robot collaboration, continuously promoting the practical application of intelligent manufacturing and service robots.
Media Contact
Organization: Shanghai Zhiyuan Innovation Technology Co., Ltd.
Contact Person: Jocelyn Lee
Website: https://www.zhiyuan-robot.com
Email: Send Email
City: Shanghai
Country:China
Release id:35600
The post Agibot Released the Industry First Open-Source Robot World Model Platform – Genie Envisioner appeared first on King Newswire. This content is provided by a third-party source.. King Newswire makes no warranties or representations in connection with it. King Newswire is a press release distribution agency and does not endorse or verify the claims made in this release. If you have any complaints or copyright concerns related to this article, please contact the company listed in the ‘Media Contact’ section
Disclaimer: The views, suggestions, and opinions expressed here are the sole responsibility of the experts. No Funds Pulse journalist was involved in the writing and production of this article.